摘錄於Version Control with Subversion (for Subversion 1.5)之電子書
針對在svn常見的名詞 "changesets", 提供了清楚的定義
Changesets
Before we proceed further, we should warn you that there's going to be a lot of discussion of “changes” in the pages ahead. A lot of people experienced with version control systems use the terms “change” and “changeset” interchangeably, and we should clarify what Subversion understands as a changeset.
Everyone seems to have a slightly different definition of changeset, or at least a different expectation of what it means for a version control system to have one. For our purposes, let's say that a changeset is just a collection of changes with a unique name. The changes might include textual edits to file contents, modifications to tree structure, or tweaks to metadata. In more common speak, a changeset is just a patch with a name you can refer to.
In Subversion, a global revision number N names a tree in the repository: it's the way the repository looked after the Nth commit. It's also the name of an implicit changeset: if you compare tree N with tree N−1, you can derive the exact patch that was committed. For this reason, it's easy to think of revision N as not just a tree, but a changeset as well. If you use an issue tracker to manage bugs, you can use the revision numbers to refer to particular patches that fix bugs—for example, “this issue was fixed by r9238.” Somebody can then run svn log -r 9238 to read about the exact changeset that fixed the bug, and run svn diff -c 9238 to see the patch itself. And (as you'll see shortly) Subversion's svn merge command is able to use revision numbers. You can merge specific changesets from one branch to another by naming them in the merge arguments: passing -c 9238 to svn merge would merge changeset r9238 into your working copy.
簡要說明: "changesets"在svn中, 真正代表的意義是, 在commit時, 此時間點下, 異動到的檔案, 皆可視為"changesets", 而使用者可以藉由svn log -r9238, 或svn diff -r9238, 清楚得知該次異動到檔案
衍生說明: 同一時間點內, 儘可能增修一個bug, 一個fuction , 一個procedure, 隨即進行一次commit, 極力不建議增修多個bug, 多個fuction, 多個procedure, 才進行一次的commit
舉例說明: user A增加一個fuction CallPhone(), 也修改一個function SetRing(), 實際上2個function是不相干的, CallPhone()是新增需求, SetRing()是修改流程, 卻同時進行commit, 當日後user B發現CallPhone()有問題, 卻很難將之移除, 須額外花費時間判斷哪些部份的程式碼是因應Call Phone而增修的, 造成極大的困擾及風險
2011年9月11日 星期日
2010年12月5日 星期日
core dump 命名設定
往往每一發現core dump產生, 系統預設產生檔名為core.pid, 還得由log去查看是哪支程式的pid, 實在很不直覺化
首先, linux針對code dump的命名設定, 參考於/proc/sys/kernel/core_pattern
預設值為"core", 可使用的命名變數如下:
個人習慣core dump可以得知哪支程式產生, 所以命名式為 "core.%e.%p"
以上大功告成!!
首先, linux針對code dump的命名設定, 參考於/proc/sys/kernel/core_pattern
$> more /proc/sys/kernel/core_pattern
預設值為"core", 可使用的命名變數如下:
%p : pid
%% : output one %
%u : uid
%g : gid
%s : signal number
%t : time of dump
%h : host name
%e : executable filename
%: % is dropped
%: both are dropped
個人習慣core dump可以得知哪支程式產生, 所以命名式為 "core.%e.%p"
$> echo "core.%e.%p" > /proc/sys/kernel/core_pattern
或
$> vi /etc/sysctl.conf
kernel.core_pattern = core.%e.%p
以上大功告成!!
2010年12月4日 星期六
connect() raise No route to host and recv() raise Resource temporarily unavailable
當client socket 與 server 正常連線下, 中繼switch的網路線被短暫拔插時..
(1) close client socket
正常程序client socket當send(), 會偵測到網路已斷開, 此時須close()
(2) try to connect to server
正常程序client socket會試著建立新連線, 但由於switch須一段時間才會恢復,
connect()會引發ENETUNREACH (No route to host), 表示無法順利連線,
此時建議sleep()數秒, 再試著重新connect(), 直到成功建立連線
(3)send alive mssage and recv ack
正常程序client socket成功建立連線後, 會試著send() alive massage,
並recv() ack, 以表示雙方ap已確立建立連線..
若recv() with non-block, 猜測server此時重新binding socket,
recv()會引發EAGAIN (Resource temporarily unavailable),
表示sokcet無任何資料可以讀取, 建議捨棄此次alive massge作業,
sleep()數秒, 再進行一次send() alive message,
亦或是, sleep()1秒, 再進行recv() ack, 若重覆3次, 依舊無資料可讀取,
捨棄此次alive massage作業, sleep()數秒, 再進行一次send() alive message
man recv ::
If no messages are available at the socket, the receive calls wait for a message to arrive, unless the socket is nonblocking (see fcntl(2)), in which case the value -1 is returned and the external variable errno set to EAGAIN. The receive calls normally return any data available, up to the requested amount, rather than waiting for receipt of the full amount requested.
(1) close client socket
正常程序client socket當send(), 會偵測到網路已斷開, 此時須close()
(2) try to connect to server
正常程序client socket會試著建立新連線, 但由於switch須一段時間才會恢復,
connect()會引發ENETUNREACH (No route to host), 表示無法順利連線,
此時建議sleep()數秒, 再試著重新connect(), 直到成功建立連線
(3)send alive mssage and recv ack
正常程序client socket成功建立連線後, 會試著send() alive massage,
並recv() ack, 以表示雙方ap已確立建立連線..
若recv() with non-block, 猜測server此時重新binding socket,
recv()會引發EAGAIN (Resource temporarily unavailable),
表示sokcet無任何資料可以讀取, 建議捨棄此次alive massge作業,
sleep()數秒, 再進行一次send() alive message,
亦或是, sleep()1秒, 再進行recv() ack, 若重覆3次, 依舊無資料可讀取,
捨棄此次alive massage作業, sleep()數秒, 再進行一次send() alive message
man recv ::
If no messages are available at the socket, the receive calls wait for a message to arrive, unless the socket is nonblocking (see fcntl(2)), in which case the value -1 is returned and the external variable errno set to EAGAIN. The receive calls normally return any data available, up to the requested amount, rather than waiting for receipt of the full amount requested.
2010年2月18日 星期四
當VMWare出現"The Virtual Machine appears to be in use..."
當執行VMware時, 偶發一次發生出現這樣的訊息, "The Virtual Machine appears to be in use..."
其guest os再也無法開機, 原來它會建立lock file or lock path,
一旦偵測有其lock file path存在, 便不會讓相同的guest os重覆執行, 是種保護機制,
所以依照下述步驟, 便可解除這樣的問題:
1. 進入virtual machine安裝guest os的資料夾
2. 將*.lck的資料夾, 重新更名為其它名稱, 亦或者將它們刪除
3. 重新啟動guest os
其guest os再也無法開機, 原來它會建立lock file or lock path,
一旦偵測有其lock file path存在, 便不會讓相同的guest os重覆執行, 是種保護機制,
所以依照下述步驟, 便可解除這樣的問題:
1. 進入virtual machine安裝guest os的資料夾
2. 將*.lck的資料夾, 重新更名為其它名稱, 亦或者將它們刪除
3. 重新啟動guest os
2010年2月13日 星期六
調整TCP TIME_WAIT, 快速釋放連線資料
在參閱TCP TIME_WAIT的釋義一文後,
了解到系統須等待2MSL時間, 才進入CLOSED狀態, 關閉連線
在linux RedHat AS4中, 執行$>netstat -tnao, 會發現到,
主動斷線端處理TIME_WAIT後, 須等待60秒, 才會真正關閉連線
哪有什麼方式可以縮短TIME_WAIT的等待時間呢??
方法一.
$> vi /etc/sysctl.conf
## 表示開啟重用機制, 允許socket在TIME_WAIT狀態下, 重新bind新的socket
net.ipv4.tcp_tw_reuse = 1
## 表示開啟回收機制, 允許socket在TIME_WAIT狀態下, 被快速回收, 毋須等待2MSL
net.ipv4.tcp_tw_recycle = 1
$> /sbin/sysctl -p ## 使上述設定生效
方法二.
## 查看系統預設TIME_WAIT時間
$> more /proc/sys/net/ipv4/tcp_fin_timeout
## 修改系統預設TIME_WAIT時間
$> echo 30 > /proc/sys/net/ipv4/tcp_fin_timeout
方法三.
在setsockopt()時, 設置SO_LINGER之屬性,
linger.l_onoff 表示開啟延遲功能
linger.l_linger 表示延遲時間為0秒
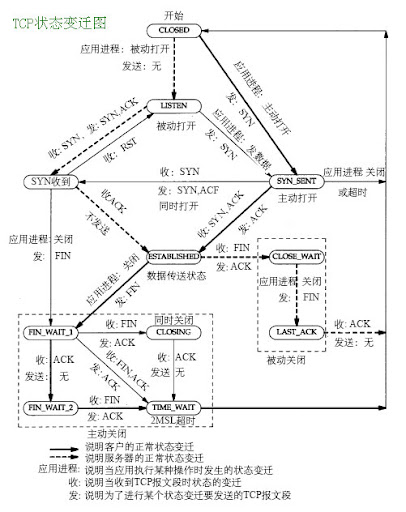
了解到系統須等待2MSL時間, 才進入CLOSED狀態, 關閉連線
在linux RedHat AS4中, 執行$>netstat -tnao, 會發現到,
主動斷線端處理TIME_WAIT後, 須等待60秒, 才會真正關閉連線
哪有什麼方式可以縮短TIME_WAIT的等待時間呢??
方法一.
$> vi /etc/sysctl.conf
## 表示開啟重用機制, 允許socket在TIME_WAIT狀態下, 重新bind新的socket
net.ipv4.tcp_tw_reuse = 1
## 表示開啟回收機制, 允許socket在TIME_WAIT狀態下, 被快速回收, 毋須等待2MSL
net.ipv4.tcp_tw_recycle = 1
$> /sbin/sysctl -p ## 使上述設定生效
方法二.
## 查看系統預設TIME_WAIT時間
$> more /proc/sys/net/ipv4/tcp_fin_timeout
## 修改系統預設TIME_WAIT時間
$> echo 30 > /proc/sys/net/ipv4/tcp_fin_timeout
方法三.
在setsockopt()時, 設置SO_LINGER之屬性,
linger.l_onoff 表示開啟延遲功能
linger.l_linger 表示延遲時間為0秒
struct linger opt_linger = { 0,0 };
opt_linger.l_onoff = 1;
opt_linger.l_linger = 0;
if (::setsockopt(SSock, SOL_SOCKET, SO_LINGER, (const char *)&opt_linger, sizeof(linger)) == -1) {
ap_log (ERROR, "setsockopt(LINGER) fail");
return false;
}

2009年8月26日 星期三
如何防止彊屍程序(zombie)的產生??
當執行program ex1程式片段後, 試著以kill prog1的方式終止prog1之程序,
結果查詢目前各程序執行狀況(ps -ef), 發現出現[prog1],
接下來無論怎麼kill prog1, 都無法將其消滅, 唯有中止main(), 它才會消失...
原來它就是僵屍程序(zombie), 何謂僵屍程序呢??
補救辦法是殺死僵屍程序的父程序(僵屍程序的父程序必然存在),
僵屍程序成為"孤兒程序",過繼給pid=1的程序init,init始終會自行負責清理僵屍進程。
僵屍程序之範例:
解決一.
在父程序設置SIGCHLD信號的處理函式, 使其父程序自動忽略子程序的狀態變更,
但長期常駐程式, 可能不適用, 難保不會出現系統資源耗用的現象
解決二.
在父程序設置SIGCHLD信號的處理函式, 並呼叫waitpid(), 等待捕獲子程序的返回狀態
解決三.
呼叫2次fork(), 父程序呼叫fork(第一次)產生子程序, 子程序再呼叫fork(第二次)產生孫程序,
隨即子程序終結死亡, 此時孫程序變為"孤兒程序",init程序會接管孫程序, 變成它的父程序,
而init程序會自行負責處理SIGCHLD信號
結果查詢目前各程序執行狀況(ps -ef), 發現出現[prog1]
接下來無論怎麼kill prog1, 都無法將其消滅, 唯有中止main(), 它才會消失...
原來它就是僵屍程序(zombie), 何謂僵屍程序呢??
在fork()/execve()過程中,假設子程序結束時父程序仍存在,
而父程序fork()之前既沒設置SIGCHLD信號處理函數調用waitpid()等待子進程結束,
又沒有設置忽略該信號,則子程序成為僵屍程序,無法正常結束,
即使是root身份kill -9也不能殺死僵屍程序。
補救辦法是殺死僵屍程序的父程序(僵屍程序的父程序必然存在),
僵屍程序成為"孤兒程序",過繼給pid=1的程序init,init始終會自行負責清理僵屍進程。
僵屍程序之範例:
int main (int argc, char *argv[])
{
char *prog_list = {"prog1","prog2", "prog3"};
for (int i=0; i<3; i++) {
char *arg_list = {prog_list[i], NULL};
forkExecProc (prog_list[i], arg_list);
}
while (true) {
sleep (2);
}
return 0;
}
int forkExecProc (char *prog, char **arg_list)
{
pid_t child;
/* check if fork fail that first child is not created */
if ((child = fork ())< 0) {
fprintf (stderr, "fork error");
} else if (child == 0) { /* run into first child */
fprintf (stdout, "fork to execute : [%s]\n", arg_list);
/* replaces the current process image with a new process image */
execvp(prog, arg_list);
/* if execvp() is return, mean that on error */
fprintf(stderr, "execvp error");
exit(0);
}
return child;
}
解決一.
在父程序設置SIGCHLD信號的處理函式, 使其父程序自動忽略子程序的狀態變更,
但長期常駐程式, 可能不適用, 難保不會出現系統資源耗用的現象
int main (int argc, char *argv[])
{
signal (SIGCHLD,SIG_IGN); //設置SIGCHLD
char *prog_list = {"prog1","prog2", "prog3"};
for (int i=0; i<3; i++) {
char *arg_list = {prog_list[i], NULL};
forkExecProc (prog_list[i], arg_list);
}
while (true) {
sleep (2);
}
return 0;
}
int forkExecProc (char *prog, char **arg_list)
{
...
}
解決二.
在父程序設置SIGCHLD信號的處理函式, 並呼叫waitpid(), 等待捕獲子程序的返回狀態
void sig_fork(int signo)
{
pid_t pid;
int stat;
// 呼叫waitpid(),等待子程序返回, 若無子程序返回, 也不一直等待
pid=waitpid(0,&stat,WNOHANG);
return;
}
int main (int argc, char *argv[])
{
signal (SIGCHLD, sig_fork); // 設置SIGCHLD, 並呼叫waitpid(), 捕獲子程序的返回狀態
char *prog_list = {"prog1","prog2", "prog3"};
...
return 0;
}
int forkExecProc (char *prog, char **arg_list)
{
pid_t child;
/* check if fork fail that first child is not created */
if ((child = fork ())< 0) {
fprintf (stderr, "fork error");
} else if (child == 0) { /* run into first child */
fprintf (stdout, "fork to execute : [%s]\n", arg_list);
/* replaces the current process image with a new process image */
execvp(prog, arg_list);
/* if execvp() is return, mean that on error */
fprintf(stderr, "execvp error");
exit(0);
}
/* no block to wait for first child chang state */
/* must be use signal (SIGCHLD, xxx) to fetch child change state */
waitpid (-1, NULL, WNOHANG); // 父程序呼叫waitpid(),不阻塞等待子程序的返回狀態, 待引發SIGCHLD
return child;
}
解決三.
呼叫2次fork(), 父程序呼叫fork(第一次)產生子程序, 子程序再呼叫fork(第二次)產生孫程序,
隨即子程序終結死亡, 此時孫程序變為"孤兒程序",init程序會接管孫程序, 變成它的父程序,
而init程序會自行負責處理SIGCHLD信號
int main (int argc, char *argv[])
{
char *prog_list = {"prog1","prog2", "prog3"};
for (int i=0; i<3; i++) {
char *arg_list = {prog_list[i], NULL};
forkExecProc (prog_list[i], arg_list);
}
while (true) {
sleep (2);
}
return 0;
}
int TaskHandler::forkExecProc (char *prog, char **arg_list)
{
pid_t child;
/* check if fork fail that first child is not created */
if ((child = fork ())< 0) { // 產生子程序
fprintf (stderr, "fork error");
} else if (child == 0) { /* run into first child */
/* check if fork fail that second child is not created */
if ((child = fork ())< 0) { // 產生孫程序
fprintf (stderr, "fork error");
}
else if (child > 0) { /* run into parent of second child whick is first child */
/* terminate the first child, in order that second child's parent becomes init */
exit(0); // 子程序自行終結, 此時孫程序被init接管為它的父程序
}
else { /* run into second child */
// 孫程序繼續執行下列步驟
fprintf (stdout, "fork to execute : [%s]\n", arg_list);
/* replaces the current process image with a new process image */
execvp(prog, arg_list);
/* if execvp() is return, mean that on error */
fprintf(stderr, "execvp error");
exit(0);
}
}
/* wait for first child chang status */
waitpid (child, NULL, 0); // 父程序呼叫waitpid(), 等待子程序終結,並捕獲返回狀態
return child;
}
2009年7月5日 星期日
dblink of postgresql
現今在承接南部第一大鋼鐵廠的資訊系統工程後, 遭遇到必須連線至遠端的postgresql,
擷取所需的資料, 並不透過Tcp/Ip Socket進行訊息封包的傳送
便回想當初在第一家電子公司當小小MIS, 便曾使用過Oracle其一功能, 簡稱db link,
不必在ap上, 另外多建立一個資料庫連線, 可利用原資料庫連線擷取另遠端資料庫的功能
於是上網google, 果不其然postgresql也支援著類似的功能, 不愧是自由軟體界資料庫第一把交椅,
而安裝動作也很簡單, 整理如下所述:
## 安裝 (至存放原始安裝檔之路徑)
$> cd contrib/dblink
$> make
$> make install
## dblink相關函式安裝 (至postgresql安裝目錄之路徑)
## 此時會新增兩個檔案 pgsql/lib/dblink.so(函式庫) & pgsql/share/contrib/dblink.sql(語法安裝)
$> su - postgres
$> cat dblink.sql psql
參考網址: db link sql
擷取所需的資料, 並不透過Tcp/Ip Socket進行訊息封包的傳送
便回想當初在第一家電子公司當小小MIS, 便曾使用過Oracle其一功能, 簡稱db link,
不必在ap上, 另外多建立一個資料庫連線, 可利用原資料庫連線擷取另遠端資料庫的功能
於是上網google, 果不其然postgresql也支援著類似的功能, 不愧是自由軟體界資料庫第一把交椅,
而安裝動作也很簡單, 整理如下所述:
## 安裝 (至存放原始安裝檔之路徑)
$> cd contrib/dblink
$> make
$> make install
## dblink相關函式安裝 (至postgresql安裝目錄之路徑)
## 此時會新增兩個檔案 pgsql/lib/dblink.so(函式庫) & pgsql/share/contrib/dblink.sql(語法安裝)
$> su - postgres
$> cat dblink.sql psql
參考網址: db link sql
訂閱:
文章 (Atom)